On May 25th, I published this post covering some scenarios on how to use Site Recovery Manager & Active Directory. Michael White from VMware responded with some good info. He had an awesome suggestion of using a script to cold clone a DC daily to use for testing.
Let’s take a look at some ways we can get this done:
Cloning a Domain Controller for SRM Recovery Plan testing
In the instances described below, there are a few expectations:
- You have a dedicated test network that cannot communicate with production systems
- You have at least one DC running at the Recovery Site (two or more is preferred)
- Your Active Directory is running native replication to your Recovery Site
- AD Change Notification is enable – Optional, but speeds up change replication
- Lastly, a PowerShell PowerCLI script to do the cloning for you – this wouldn’t be right without some PowerShell!
It is best to have more than one Domain Controller at the Recovery Site. Why? When cold cloning the VM, it will be powered off. If you only have one DC at the Recovery Site, your AD at that site will be 100% offline. True, it’s only for as long as the VM is offline for the clone, but I don’t like the idea of being vulnerable, if even for a few minutes. Here’s my recommendation: build a mirror of your Protected Site and make sure all DCs are Global Catalogs. If this is not feasible, have at least two DCs at the recovery site, both being Global Catalogs.
Now that you’ve got your Recovery Site AD all set up, your DC for cloning should not be your bridgehead. This way, while your DC is offline for cloning, the two AD sites are still replicating data, and when the DC comes back online, it replicates locally with it’s bridgehead. It’s just an additional step to keep our vulnerability as low as possible. If you have several DCs, all the others are still replicating because the bridgehead is still up.
What your script should do
Perhaps another blog post is in order with this script! In the mean time, here are some steps it should accomplish:
- Issue graceful shutdown the VM
- Check back in 5-10 minutes to see if it’s powered off
- If not, wait another 5-10 minutes and check again – You don’t want to power it off, since you want a clean file system
- Check to see if cloned DC already exists, if yes, power off & delete from disk
- Initiate clone of VM
- Validate cloned DC is on test network
- Power on VM
Now that we have a script, how and when should we run it?
Running the clone as part of your Recovery Plan
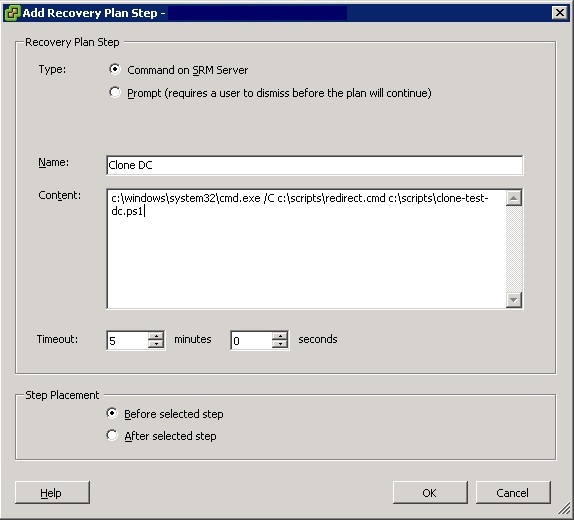
Why wouldn’t you run this way? Well, because of that timeout. There is potential for your test plan to increase by a large amount of time. If you only have a few VMs in your test plan, it may only take 5 minutes to run. Throw in a DC clone and it may quadruple the test plan time, you may also need a script to power off & delete the DC VM when done, too, but that doesn’t add much time. You don’t want to sit around waiting for your test plan to spin up your DR test, which leads me to this…
Scheduling the clone script regularly
In my opinion, this is ideal. Chances of a computer account changing it’s password right before your test are slim, although possible. You can schedule the script to run nightly, or whatever frequency you choose, and schedule your tests around the cloning time. Now, whenever you run a test plan, there’s a DC already waiting for you on your test network.
The principal draw back to this method is there’s a potential for you to be down while a DC is down being cloned. Preferably, you’ll have more than one DC at the Recovery Site, so the AD state will be degraded and not offline.
As always, feel free to comment or email me, this is a touchy subject, so I’m very open to discussion and interested in what others are doing here.
Nice – thanks! Great for customers.
Great Article – Did you ever write a post on the actual script and the powershell required?
I have not, but it’s something I could look into doing. If you want something like that, I can definitely try to crank one out :D
If possible, I’m new to VMware but not AD. If you have a script, I would like to take a look at it. Right now, I’m trying to stage DC refresh by using virtual DCs.
Greg, I don’t have one, but can help you get started!
This is a great guide, but leaves a few questions unanswered. In particular, we’re rolling out SRM 6 in a vSphere 6 Standard environment. We have HP MSA SANs doing SAN replication using their Remote Snap software. We’ve already staged 99% of this, including setting up a DC and vCenter+SRM in an unreplicated volume at each site. So far, so good – right?
The problem is we have several systems (e.g. our remote access VPN) that only support one host entry for LDAP/DHCP/DNS. Originally, we figured we’d point this at “DC03” which hosts the DHCP server and is a valid AD DC.
Now that we’re rolling out the DR site, this becomes a bit more complicated… So far we have the following:
1) “DC02” is the Production site DC. It is currently on an isolated datastore (no SAN replication) and would presumably NOT fail over to the DR site.
2) “DC03” is another Production site DC and also hosts the DHCP server (we haven’t set up DHCP replication under 2012R2 yet). All systems that use LDAP/DNS/NTP/DHCP calls that DON’T support multiple entries use this host (this includes several firewalls and the VPN system, switch and Firewall IP Helper for DHCP Relay, etc.)
3) “DRDC01” is the DR site DC; also on an isolated datastore (on the DR SAN) with no replication.
I can think of a few options, but am trying to figure out the best:
1) First, I think all DCs need to be a GC.
2) If we allow “DC03” to fail over and preserve the production network subnet (no readdressing), all AD/DHCP/etc. clients continue to point to that DC’s IP.
a) When SRM fails over, this DC would come up as if we’d hard rebooted it; the “DRDC01” would have stayed up and would have the latest AD replica regardless of the state of the “DC03” failover VM.
b) During testing, we could just use the ‘DC03’ failover within the test environment. So long as we ensure that the test environment CANNOT talk to the production or DR active environments, we could presumably use this for the test authentication/etc. (i.e. so long as ALL test VMs are on isolated/locally-routed networks only).
c) During Failover, ‘DC02’ is dead/unreachable anyway.
d) QUESTION: During failover, “DRDC01” stays active throughout. Does it take over the PDCE role? How does “DC03” come up into the new production environment and resolve any AD drift or versioning? (Assume that there is routing between the new production “DC03” at the DR site and the active “DRDC01” at the DR site.)
Alternately, I could see leaving “DC03” and “DC02” out of replication so that NO DCs are replicated. In that case, we would lose both DC03 and DC02 during a site failure and have to manually change anything (DHCP Relay, etc.) over to “DRDC01”. This would be easiest for DHCP if we can set up DHCP clustering using 2012R2 so that the DHCP database is also natively replicated.
Oh yeah – and in this case, what system do we clone for testing? Do we set up the PDCE and DHCP on e.g. “DC03” and then clone that into the DR testing environment (across the WAN)? This preserves the correct IP addressing from the production network within the test environment, but could take somewhat longer since we need to clone across the WAN…
Thanks, and I agree, there’s so much more to this topic that can be covered on this post. I’ll try to address your points/questions, along with the standard disclaimer of no warranty :P
Correct
There’s no automation, you’d have to manually do this, via ‘seizing the role’, but I would NOT recommend that. Once “DC03” comes back online, it will still believe it is the PDCe and cause other problems, and possibly corrupt the directory (or cause inconsistencies at the very least).
AD keeps track of versioning via an “Update Sequence Number”, or USN. I don’t want to go too deep into USN and how all changes are tracked, but DC03 would come online and talk to the other replication partners. Assuming DC02 is in the same AD site, but now dead, it moves on to the next DC, “DRDC01”, and does what’s basically a USN check. “DC03” should be able to determine where it left off via USN change tracking, and request the changes needed, no different than if it was a physical box that went down for a short period of time for physical maintenance. In the event “DC03” is offline for too long (multiple weeks), it can come online and think it’s authoritative and actually deny logins if passwords have changed. I had that happen on a sick DC that wasn’t replicating for 30+ days. Rebooting it actually caused more harm that good. Something to think about, or plan for, if your production site is offline for an extended amount of time (seize FSMO roles, plan to build new DCs, then transfer roles, etc).
In that scenario, you’d want to clone “DRDC01” to simulate all the tasks needed to make “DRDC01” the main master (DHCP, FSMO roles, etc). The idea is that you get as close to a DR event as possible, thus doing all testing with “DRDC01”.
Is using a form of global load balancing, or round-robin DNS at the very least, out of the question for other services like LDAP for authentication? Putting DNS servers behind a load balancer may feel a little weird, and honestly not something I’ve seen implemented, but maybe an option?
In John’s question above, since the goal was to “test” a recovery plan, the recovered VMs in the Test Network will maintain their IP and DNS records. I believe that was the reason of his cloning DC03 in order to preserve the correct IP addressing from the Production network within the Test Network. In Luke’s response, “.. The idea is that you get as close to a DR event as possible, thus doing all testing with “DRDC01” – however, in a true DR event, the recovered VMs will be assigned with new IPs corresponding to security zone in the recovery site. At that point, using DRDC01 makes sense (in a true DR event). But, the focus here is to “Test” recovery plan and not “Run” recovery plan – it is not clear to me that we should clone DRDC01 instead of DC03 as John had suggested? Can Luke please elaborate a bit more?
I got a question of my own regarding ‘test recovery plan”. In a typical 3-tier enterprise architecture, the Web, App, DB VMs are on separate VLANs with different IP subnet ranges. By default, after a test recovery plan is exercised, these VMs are recovered to a test network with a single port group (as an example, srmpg-8171-recovery-plan-390084 in one of my test cases). It was not clear to me how SRM works in this case. What I observed was that VMs in the same VLAN in Production can still communicate with each other in the Test Network. However, VMs in different VLANs in Production where they could ping each other, can no longer ping each other in the Test Network. The proper routing and firewall configuration in Production apparently was not replicated in the Test Network (correct me if this statement is incorrect). If that’s the case, what’s the recommended remedy in order to replicate the network configuration (VMs’ IP addresses, routing, and firewall configs) in Production into the Test Network?
Since I didn’t have a way to recreate Production network setting into the Test Network, one way to work around was to re-IP VMs such that these VMs were placed in a flat network (all were on the same VLAN) in order to communicate with each other in the Test Network. However, in doing so, I was forced to update AD/DNS records in order to be able to authenticate properly. There are multiple layers DCs in our environment, and it required substantial effort to update AD/DNS records and I still have not been able to get it work properly.
In summary, for a business application running on a typical 3-tier enterprise architecture, what’s VMware’s recommended solution in exercising “test recovery plan” with SRM? Is there a way to replicate Production network into the Test Network? Otherwise, what’s recommended solution to handle AD/DNS issue in a flat Test Network? Thanks!