vCenter’s not responding properly
Scroll down to bottom for TL;DR version
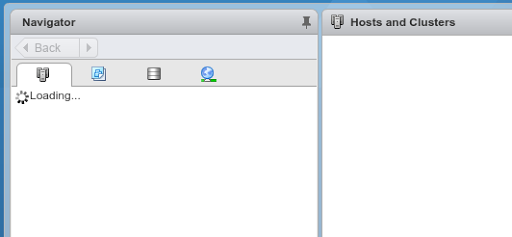
I got a text message this evening from a colleague of mine (@FrankRax) stating our lab was down. I tried to hit the vCenter and the hosts & clusters view wouldn’t load in the web client, just left me with the spinning wheel:
Okay, that’s fine, so I’ll check the VAMI, or Management UI of the VCSA, but then I got really scared when I saw this:
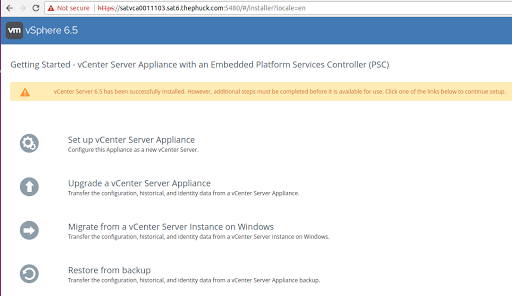
This isn’t a fresh install, it’s been a lab for a long time, actually even upgraded to 6.5u1 not that long ago. Now I know for a fact something’s gone wrong, so I launched the host client on each node in the cluster until I found the vCenter Server Appliance VM and launched the console, and was pretty much horrified at what I saw
the following content may be disturbing to some audiences, viewer discretion is advised
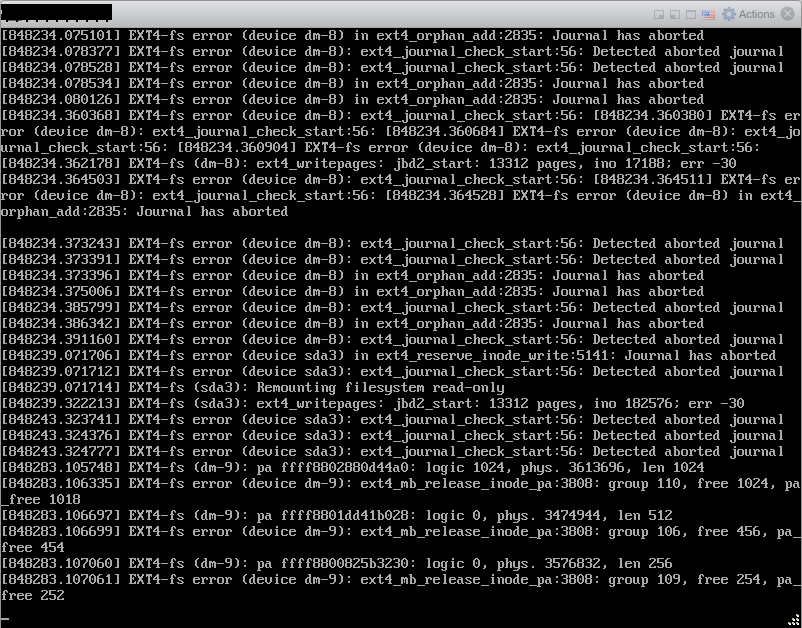
Now, Frank & I have ran into this before and the typical “fsck /dev/sda3” fixed it without issue (you can see that partition listed in the screenshot, along with dm-8 and dm-9, which I dunno what those are). We followed this https://github.com/vmware/photon/blob/master/docs/photon-os-troubleshooting-guide.md#fsck last time, so we turned to it now, but just the “fsck /dev/sda3” didn’t actually work. The first time I ran the fsck, it fixed some issues, but rebooting yielded different results than the previous failed boot. It still failed, but this time it went by so fast I couldn’t exactly see what failed:
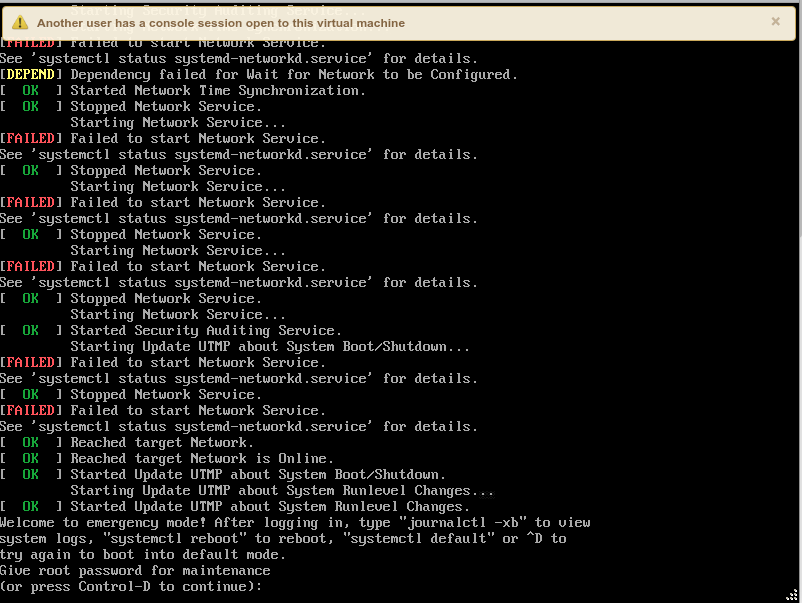
I tried running fsck on /dev/sda3 and it said it was mounted, and I couldn’t unmount it because it’s in use (the system was using it and I couldn’t unmount it, plain & simple) and also ran fsck /dev/mapper/log_vg-log, as per the previous time the filesystem became corrupt. That picked up & fixed errors, but upon reboot, I ended up right back where I was before. Again, the error went by so fast I really don’t know what it was, but I could see the services weren’t running. In that link above, it referenced rebooting and hitting “e” at the Photon OS splash screen, then editing the boot line to get into an emergency mode, effectively. This will allow you to run fsck on partitions that were mounted previously.
Once I booted into emergency mode, I ran a “umount /dev/*” to unmount everything it can, then ran a “cat /etc/fstab” to see all partitions and volume groups it mounts, then ran fsck -fy on every single one of them.
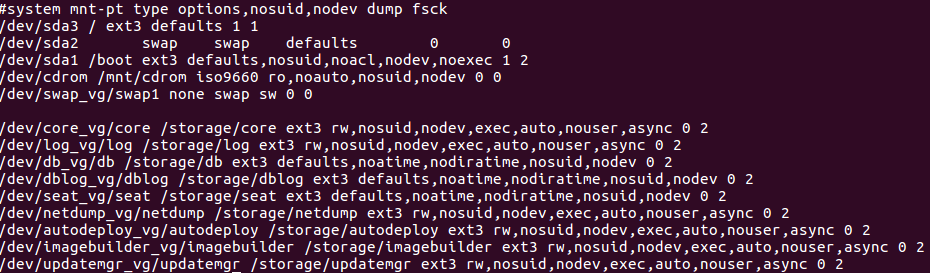
Yours may vary slightly, but all the volume groups (labeled with vg) should be the same. I started at sda3 and worked my way down the line (skipping cdrom & swap) and got errors on log_vg/log when I first ran it above, as well as imagebuilder_vg/imagebuilder when I ran it on all of the volumes. Now that all partitions/volumes were passing fsck, I decided to reboot and rejoiced when I was greeted with the familiar vcsa login prompt! I’m guessing that dm-8 and dm-9 somehow correlate to log_vg and imagebuilder_vg, but it’s purely a guess and could be a coincidence that I saw three different devices listed in the console and happened to fix three volumes/partitions with fsck. I’m also guessing that “dm” stands for device mapper, from the other fsck I ran above against /dev/mapper/log_vg-log. Again, purely speculation.
So…in the future, should I run across this again, here’s what I’d do right from the start (this is the TL;DR version):
- *SNAPSHOT YOUR VM*
- Reboot the VCSA and press ‘e’ when you see the Photon OS splash screen
In the GNU GRUB edit menu, go to the end of the line that starts with linux, add a space, and then add the following code exactly as it appears below:- systemd.unit=emergency.target
- Then hit F10
- type shell to get a shell prompt
- type “umount /dev/*”
- type “cat /etc/fstab”
- run fsck -yf on every mount point listed
- type “systemctl reboot” and hope it comes back
I had this happen to me for the first time ever and this post saved me. Thank you for sharing your knowledge.